去年年底OpenAI发布的ChatGPT就已经算是四个二了,令其他科技大佬还有赶超的机会,但没想到仅过去4个月,OpenAI又发布了更加强大的GPT-4,其功能之强大绝对堪称“王炸”,相比ChatGPT只能识别文本,GPT-4能够处理更加复杂的图像信息,并只需1-2秒制作出网站。
GPT-4的强大之处

当地时间3月14日,OpenAI公开发布大型多模态模型GPT-4,与ChatGPT所用的模型相比,GPT-4不仅能够处理图像内容,且回复的准确性有所提高。目前GPT-4没有免费版本,仅向ChatGPT Plus的付费订阅用户及企业和开发者开放。
“这是OpenAI努力扩展深度学习的最新里程碑。”OpenAI介绍,GPT-4在专业和学术方面表现出近似于人类的水平。例如,它在模拟律师考试中的得分能够排进前10%左右,相比之下,GPT-3.5的得分只能排在倒数10%左右。
与此前的GPT系列模型相比,GPT-4最大的突破之一是在文本之外还能够处理图像内容。OpenAI表示,用户同时输入文本和图像的情况下,它能够生成自然语言和代码等文本。
目前图像处理功能还未公开,不过该公司在官网上展示了一系列案例。例如,输入如下图片并询问“这张图片有什么不寻常之处”,GPT-4可作出回答“这张照片的不同寻常之处在于,一名男子正在行驶中的出租车车顶上,使用熨衣板熨烫衣服。”

在官方演示中,GPT-4几乎就只花了1-2秒的时间,识别了手绘网站图片,并根据要求实时生成了网页代码制作出了几乎与手绘版一样的网站。
除了普通图片,GPT-4还能处理更复杂的图像信息,包括表格、考试题目截图、论文截图、漫画等,例如根据专业论文直接给出论文摘要和要点。
与此前的模型相比,GPT-4的准确性有所提高。OpenAI称,该公司花费6个月的时间,利用对抗性测试程序和ChatGPT的经验教训迭代调整GPT-4,从而在真实性、可操纵性和拒绝超出设定范围方面取得了有史以来最好的结果,“至少对我们而言,GPT-4训练运行前所未有地稳定,成为首个能够提前准确预测其训练性能的大型模型。”
OpenAI称,在公司内部的对抗性真实性评估中,GPT-4的得分比最新的GPT-3.5高40%,相应的“不允许内容请求的倾向”降低了 82%,根据政策响应敏感请求(如医疗建议和自我伤害)的频率提高了29%。

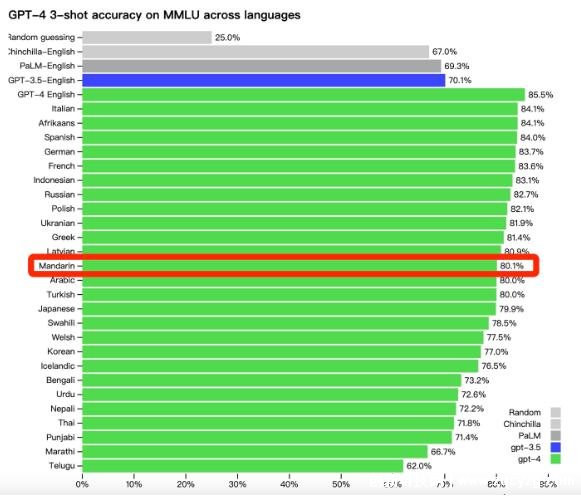
不仅是英语,该模型在多种语言方面均表现出优越性。OpenAI称,在测试的26种语言中,GPT-4在24种语言方面的表现均优于GPT-3.5等其他大语言模型的英语语言性能。其中GPT-4的中文能够达到80.1%的准确性,而GPT-3.5的英文准确性仅为70.1%,GPT-4英文准确性提高到了85.5%。
不过, 与早期的GPT模型一样,GPT-4仍然存在一定的局限性。
OpenAI称,它并不完全可靠,可能会出现推理错误 ,“GPT-4缺乏对绝大多数数据切断后(2021年9月)发生的事件的了解,并且无法从中吸取经验教训……它有时会出现简单的推理错误,它会轻信用户明显的虚假陈述,有时它会像人类一样在难题上失败,例如在它生成的代码中引入安全漏洞。”
基于此,OpenAI提醒,用户在使用语言模型时应格外小心,最好辅助以人工审查、附加上下文、或完全避免在高风险情况下使用它。
值得注意的是,GPT-4虽然于14日才正式公开,但早在一个月前,微软的新版搜索引擎必应(Bing)就已经在GPT-4 上运行。微软表示,“如果您在过去五周内的任何时间使用过新版必应,那么您已经体验过GPT-4的早期版本。”
与免费的ChatGPT不同,GPT-4目前仅向ChatGPT Plus的付费用户开放,它也将作为API(应用程序编程接口)提供给企业及开发者,开发者需进入等候名单上,将该模型集成到他们的应用程序中。
OpenAI表示,已经有多家公司将GPT-4搭载到他们的产品中,包括语言学习工具软件多邻国(Duolingo)、移动支付公司Stripe和可汗学院(Khan Academy)。



